
BigSurv18 will take place in Barcelona, Spain on October 25-27, 2018. This conference brings together international researchers, practitioners, and experts to address how promising technologies and methodologies for using massive datasets can improve, supplement, or replace data and estimates from complex surveys and censuses.
Researchers affiliated with the S3MC studies will give several presentations at BigSurv18. These presentations are listed below. When you arrive at the conference, please verify the below room locations in the final conference program, as they are subject to change.
Session: Filing the Claim for Social Media Data: Who’s Covered and Who Isn’t
Fri 26th October, 16:00 – 17:30 Location: 40.109
Evaluating Survey Consent to Social Media Linkage
Zeina Mneimneh (University of Michigan) – Presenting Author Colleen McClain (University of Michigan) Lisa Singh (Georgetown University) Trivellore Raghunathan (University of Michigan)
Researchers across the social and computational sciences are increasingly interested in understanding the utility of “big” textual data for drawing inferences about human attitudes and behaviors. In particular, discussions about whether survey responses and social media data can complement or supplement each other have been frequently raised given the differences between the two sources on their representation and measurement properties. To answer some of these questions, a growing body of work has attempted to assess the conditions under which survey data and social media data yield similar or divergent conclusions. Most of this work, however, analyzes separately the corpora of survey and social media data and compares them at a macro level. While such research has value and gives suggestive evidence about the utility of comparing or combining such data sources, it is limited in its empirical investigation of the mechanisms of divergences between the two data sources which might be due to some combination of coverage, measurement, and the data generation process (designed vs. organic). In order to expand on the research related to issues of comparability of social media posts and survey responses, few studies have conducted within-person analyses (e.g., Murphy, Landwehr, & Richards, 2013; Wagner, Pasek, & Stevenson 2015) and have tested methods of requesting consent to link a respondent’s survey responses to his or her social media data, generally in the form of asking for one’s username and for permission to access and link certain social media data. Most of this work, however, is limited either by the small yield of respondents who consent to link and provide usable information or is based on non-probability samples. Thus, systematically investigating questions on representativeness is hampered. Most importantly, issues related to consent language and the ethics of collecting and disseminating such data given their public availability (in the case of Twitter) has not been given the needed attention. In this presentation, we build on these few studies and examine the incidence and predictors of consent to Twitter linkage requests from different types of probability-based surveys: a national survey, a college survey, and a web-based panel survey. We discuss the yield of such requests not only in terms of the rate of consent, but also the richness of the Twitter data collected as measured by the frequency of tweeting. The frequency of tweeting is essential given that the usefulness of Twitter data depends on the amount of information shared by the respondent. We conclude by discussing the ethical challenges involved. These include the essential components of consent statements to collect and link social media data in a transparent way, and issues of data dissemination given their “public” nature and the network of information available on other unconsented users.
Seeking the “Ground Truth”: Assessing Methods Used for Demographic Inference From Twitter
Colleen McClain (University of Michigan) – Presenting Author Zeina Mneimneh (University of Michigan) Lisa Singh (Georgetown University) Trivellore Raghunathan (University of Michigan)
Given the relative ease of accessing and collecting Twitter data, social science researchers are increasingly using Twitter to understand social trends on a diverse set of topics — including political communication, dynamics of financial markets, forced migration, transportation patterns, and attitudes toward health practices and behaviors. These research efforts have raised questions on whether and how “big” textual data sources can supplement or replace traditional survey data collection. Any analysis of social media data seeking to draw generalizable conclusions about human attitudes, behaviors, or beliefs, however, raises important questions of 1) whether and how social media measurement diverges from more traditional survey data, and 2) whether representation of the target population can be sufficiently achieved. The latter question specifically requires identifying the socio-demographic characteristics of the individuals analyzed and adjusting for known mismatches between the social media sample and the target population on those measures. Even if the target population is social media users (as opposed to the general population), investigating any socio-demographic differences on behaviors, attitudes or beliefs requires the availability of such information. Since the rate of Twitter users who self-disclose their socio-demographic information in profiles is very low, a number of researchers in computer science and, increasingly, across the social sciences have sought to build models to predict the characteristics of the users in the Twitter samples they analyze. Yet, assessing the accuracy of those models is challenging given the need for “ground truth” measures against which the predictions can be compared. Though a variety of “ground truthing” methods exist, they have key limitations including : 1) relying on resource-heavy techniques that are prone to human error, and that do not scale easily (such as manual annotation); and 2) restricting the validity of inferences to a subset of users who disclose optional personal information, or who can be linked to other data sources, potentially jeopardizing the generalizability of the predictive models. The literature, however, is largely silent about the properties, costs, and scalability of different ground truth measures. In this light, we systematically review existing literature on predicting socio-demographic variables (including age, gender, race/ethnicity, geographic location, political orientation, and income) from Twitter data. We summarize the predictive methods and the ground truth procedures used and discuss strengths, weaknesses, and potential errors associated with each ground truth method — including those stemming from definitional differences in the constructs of interest, complexities of the unit of analysis (e.g., tweet/post versus user), and issues of sub-sampling and representation. We focus on six different ground truth methods: manual annotation; user-provided information; linked data from another social network source; linked data from a non-social network source (including a survey); distribution-based validation; and geographic assignment. We also discuss logistical and cost implications and conclude with a set of recommendations related to predictions of socio-demographic characteristics of Twitter users.
Who’s Tweeting About the President? What Big Survey Data Can Tell Us About Digital Traces
Josh Pasek (University of Michigan) – Presenting Author Colleen McClain (University of Michigan) Frank Newport (Gallup) Stephanie Marken (Gallup)
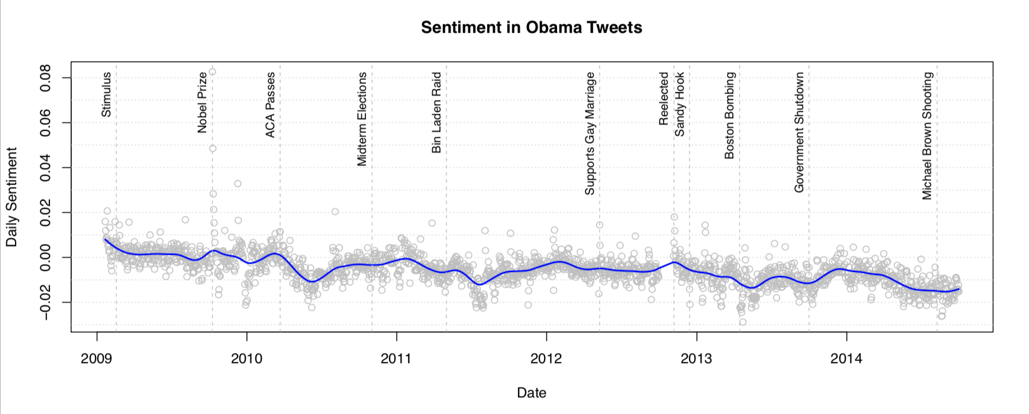
One principal concern about drawing conclusions about social phenomena from social media data stems from the self-selected nature of service users. Individuals who post on social media sites represent a subset of a group that is already unrepresentative of the public—even before considering the content of their posts, how often they post, or any number of other relevant characteristics. Hence, social researchers have long worried that trace data describe nonprobability samples. As data scientists attempt to leverage these data to generate novel understandings of society, a key overarching concern has been the need to consider the demographic attributes that distinguish social media posters from the populations researchers hope to describe. To this end, data scientists have begun to infer demographic characteristics for social media posters, with one end goal being to construct weights that allow the collection of posts to reflect public opinion. To investigate the possibility that demographic differences may be useful in improving correspondence between tweets and survey responses, we investigate the correspondence between the daily sentiment of tweets about President Obama and aggregate assessments of presidential approval of nearly one million respondents to the Gallup daily survey from 2009 into 2014. Words from more than 120 million tweets containing the keyword “Obama” were gathered using the Topsy service. Tweet text was aggregated on a daily basis and sentiment analyzed using Lexicoder 3.0 to generate a net sentiment score for each of 1,960 days for which both data streams were available. Sentiment scores were then used to predict variations in approval among the nationally representative sample of Americans interviewed by the Gallup daily survey as well as among various demographic subgroups of Americans. In general, Twitter sentiment scores tracked changes in American’s presidential approval. Both data streams displayed downward trends over the course of President Obama’s term and were positively correlated (Pearson’s r = .44). These findings track nicely with typical patterns of presidential approval. They also appeared robust to concerns about nonstationarity in time-series models, which suggests that they capture similar variations that occur in both data streams on both micro and macro levels. Notably, however, attempts to isolate the demographic groups that drive the relations between these measures proved uniformly unsuccessful. When we calculated daily approval of the president within sex, race, education, income, partisanship, and employment categories (as well as interactions of these categories), very few demographic subgroups produced correlations of greater than .44, and none of these were significantly stronger. Attempts to reverse engineer the demographic composition of individuals posting about “Obama” by estimating approval for each demographic group and regressing these onto sentiment to generate survey weights was fruitless in improving correspondence. These findings suggest that demographics are not the principal distinction underlying correspondence between social media and survey data. Instead, a demographic adjustment approach is likely doomed to fail. We believe that the results suggest that both data streams, although responsive to similar overarching societal patterns, differ principally because they are measuring substantively different things.
Session: Socializing with Surveys: Combining Big Data and Survey Data to Measure Public Opinion
Sat 27th October, 09:00 – 10:30 Location: 40.006
Social Media as an Alternative to Surveys of Opinions About the Economy
In review process for the special issue
Frederick Conrad (University of Michigan) – Presenting Author Johann Gagnon-Barsch (University of Michigan) Robyn Ferg (University of Michigan) Elizabeth Hou (University of Michigan) Josh Pasek (University of Michigan) Michael Schober (The New School)
Sample surveys have been at the heart of the social research paradigm for many decades. Recently, there has been considerable enthusiasm among researchers about new types of data, created mostly online, that may be timelier and less expensive than traditional survey data. One example is social media content, which researchers have begun to explore as a possible supplement or even substitute for survey data across a range of domains. A good example is the study by O’Connor et al. (2010) which reports reasonably high correlations between the sentiment of tweets containing the word “jobs” and two survey-based measures: Gallup’s Economic Confidence Index (r = .79) and the University of Michigan’s Index of Consumer Sentiment (ICS) (r = .64). A number of other studies have compared social media content to survey data (and related measures) and found some correspondence (e.g., Antenucci et al., 2014; Jensen & Anstead, 2013; Tumasjan et al., 2010). But not all of these initial success stories have held up. For example, analyzing data through 2011, we (Conrad et al., 2015) replicated – in fact strengthened – the relationship between sentiment of “jobs” tweets and the Michigan ICS reported by O’Connor et al. But when we included data collected after 2011, the relationship degraded rapidly, becoming small and negative. Similarly, Antenucci et al. (2014) accurately predicted US unemployment, measured by initial claims for unemployment insurance, based on the frequency of tweets containing words and phrases such as “fired,” “axed,” “canned,” “downsized,” “pink slip,” “lost job,” “unemployed,” and “seek job.” However, starting in mid 2014 the predictions and actual claims began to diverge and have not returned to previous levels of agreement. This pattern of relatively strong relationships in early years followed by highly attenuated relationships in more recent years raises serious questions about the viability of using social media content in place of survey data. The proposed presentation investigates the origins of the on-again-off-again relationship between sentiment of “jobs” tweets and the ICS by manipulating several analytic attributes and tracking the impact on the association between the two. A critical attribute not yet addressed in the literature is how the tweets are preprocessed and what categories they are sorted into (if any). We trained a classifier to assign the tweets to “job ads,” “personal jobs,” “junk,” and “other;” junk tweets actually correlated more highly with the ICS than did the other categories, suggesting that the early correlation may well have been spurious. We also manipulated the smoothing and lagging intervals (in days), the sentiment dictionary used, how sentiment was calculated (e.g., # pos/# neg words), and the particular survey questions contributing data (as opposed to the global ICS). The values of these analytic attributes can substantially affect the association between the two data sources, but the association is never high in absolute terms, increasing our skepticism that tweets (at least these) can be easily substituted for survey data. We close by proposing preliminary best practices for analyzing Twitter content and comparing it to survey
Session: Fake News! Information Exposure in Complex Online Environments
Sat 27th October, 11:00 – 12:30 Location: 40.006
When Does the Campaign Matter? Attention to Campaign Events in News, Twitter, and Public Opinion
Final candidate for the monograph Josh Pasek (University of Michigan) – Presenting Author Lisa Singh (Georgetown University) Stuart Soroka (University of Michigan) Jonathan Ladd (Georgetown University) Michael Traugott (University of Michigan) Ceren Budak (University of Michigan) Leticia Bode (Georgetown University) Frank Newport (Gallup)
Scholars of political communication have long been interested in the messages that people see and recall about candidates and elections. But because we typically do not know about salient events before they occur, it has typically not been feasible to ask targeted questions about these events in surveys as they evolve. This has rendered it difficult to determine how news media information filters down to what people are thinking about. Instead, tests of information flows have focused either on the provision of specific pieces of information or on the relative salience of various categories of issues across media. The current study uses a novel approach to identify events in news media, tweets, and open-ended survey responses that allows for the examination of where different kinds of events garner different amounts of attention and how patterns of attention compare across these data streams. Specifically, more than 50,000 respondents to the Gallup daily poll (500 each day for nearly four months) were asked open-ended questions about what they had recently seen or heard about each of the candidates in the lead-up to the 2016 U.S. Presidential election. By treating these responses as a daily bag-of-words that can be compared to the words in election news and candidate-mentioning twitter streams, we could identify terms that experienced notable spikes in attention over short periods of time. These words could then be clustered by their association with events that had occurred in the news or that people were otherwise attending to. In total, we identified more than 200 keywords that were associated with 39 distinct events that appeared across the news, Twitter, and survey data. These events varied in the extent to which they garnered attention from each data stream. For example, compared to other media, candidate comments at the Al Smith Charity Dinner were disproportionately salient in the open-ended responses whereas Hillary Clinton’s “Basket of Deplorables” comment about Trump supporters was a focus of much media attention, but was rarely mentioned in open-ended responses. Importantly, we find that the prominence of identifiable events in the news, twitter, and survey data streams is distinct from the content that is commonly extracted from textual data using topic modeling techniques. Focusing on topics and events reveals distinct patterns of attention over time and notably different stories about how media messages influence public perceptions and recall.
Session: Using Big Data for Electoral Research II: Likes, Tweets, and Votes?
Sat 27th October, 16:00 – 17:30 Location: 40.006
Gauging the Horserace Buzz: How the Public Engages With Election Polls on Twitter
Colleen McClain (University of Michigan) – Presenting Author Ozan Kuru (University of Michigan) Josh Pasek (University of Michigan)
Given the prominence of horserace news coverage, individuals are constantly bombarded with the latest poll results throughout presidential election campaigns. At the same time, today’s social media climate makes it easier than ever to engage with stories about polls online via liking, sharing, and commenting. While the effects of polling exposure on individuals’ political attitudes and behaviors are increasingly studied via surveys and experimental designs, data available via social media content provide us with new opportunities to investigate public engagement with poll coverage over the course of a campaign. Existing research suggests that polls that are close and polls that are different are more likely to be covered in traditional news media than their contemporaries, resulting in a biased set of results receiving disproportionate attention by the electorate. Whether these trends are amplified or mitigated by social media sharing, however, is an open question—and one with potential implications for perceptions of a given race, of the polling industry generally, and of the electoral process. To this end, we provide a first look at several research questions in the current work. First, we ask how much social media attention and engagement polls elicit over the course of a campaign. Second, we examine whether polls receive differential levels of attention on social media based on their deviation from polling average results at a given time or the closeness of their result. To assess these questions, we analyze a large corpus of tweets with references to polls gathered over the course of the 2016 presidential election campaign. We define a set of conditions under which we can reasonably link large volumes of tweets mentioning polls to the specific poll results they refer to, using a lookup table referencing polling results from HuffPost Pollster. In doing so, we generate a novel metric to track the “result extremity” of a given tweet in comparison to the polling average over large volumes of data and over time. We analyze trends in tweet volume as a function of survey house, result extremity, and result closeness over time using a variety of computational techniques. Building on this work, we suggest directions for microand macro-level analyses of the dynamics of poll coverage on Twitter, keeping in mind the potential inferential problems with analyzing corpora of social media data from a total error/quality perspective. Importantly, our results contribute to an understanding of the public’s engagement with and perceptions of polls and public opinion in an increasingly volatile climate for public opinion research.