
Methodology
This area of the project focuses on understanding the sampling and measurement properties of different types of social media data.
Researchers working on this project address this issue in four ways:
- Understanding the properties of different forms of ground truth data for machine learning algorithms
- Understanding the relationship between survey data and social media data
- Developing methods and best practices for inferring demographic variables
- Determining how to measure algorithmic fairness in the presence of real world data quality issues
Examining the representativeness of Twitter users
First, researchers are working to assess the degree to which Twitter account holders are representative of the population, stratified by how frequently they use Twitter, including those who do not use it.
Assessing the adequacy of demographic information about Twitter users
Currently, demographic information about Twitter users is sparse and incomplete. However, researchers are using additional data to model the relationship between characteristics of tweets (for example, emojis, word structures, and sentiments) and respondent demographics. The results will be used to multiply impute demographics on a sample of twitter handles.
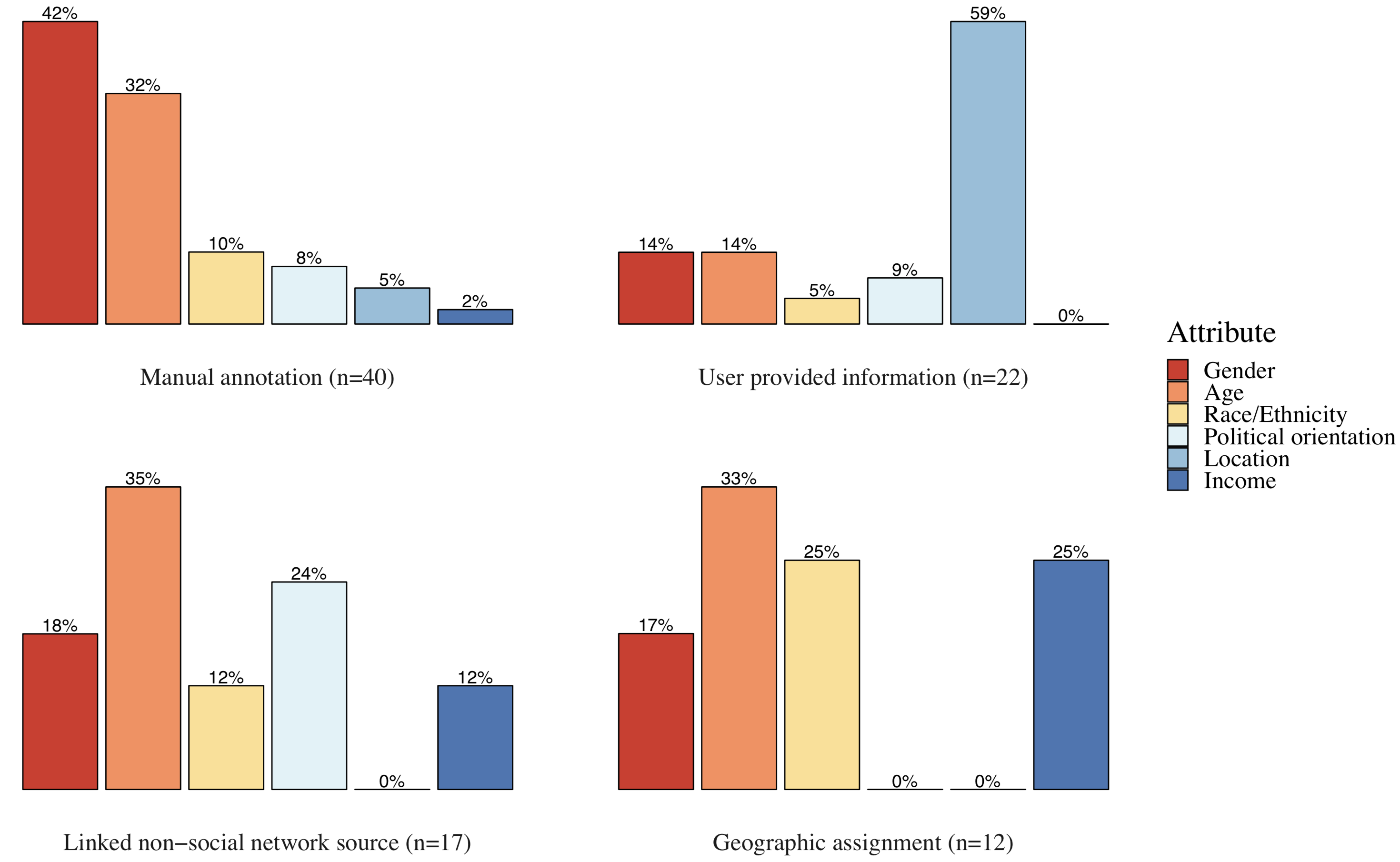
Findings from a preliminary analysis of methods for validating predictions of socio-demographics of Twitter users. The graph shows the distribution of the four most common methods, by attribute.
Develop alternative weighting procedures using imputed demographics in an attempt to improve population representativeness of Twitter account holders
Using data from the American Community Survey and the Pew Research Center surveys on internet use, researchers cross-validate the representativeness of Twitter users.
Project Team
The research team conducting analysis of the results of this project are Lisa Singh from Georgetown University and Zeina Mneimneh from the University of Michigan.
Publications and Presentations
Liu, Y., Singh, L., & Mneimneh, Z. (2021). A comparative analysis of classic and deep learning models for inferring gender and age of Twitter users. In Proceedings of the International Conference on Deep Learning Theory and Applications. Virtual.
Mneimneh, Z. & Alvarado, F. (2020, November 13). Consent to link Twitter data to survey data: A comprehensive assessment. [Conference presentation]. BigSurv20, Online.
Mneimneh, Z. (2020, March) Evaluating Survey Consent to Social Media Linkage in Three International Health Survey [Conference presentation]. Health Survey Research Methods meeting, Williamsburg, Virginia.
Mneimneh, Z., McClain, C., Singh, L., & Raghunathan, T. (Working Paper). What type of “truth” is out there? Methods for validating socio-demographic predictions from Twitter.